Programming Logic
Steps for analysing the given dataset using clustering algorithms
Pre-requisite:
Understand the dataset for any pre-processing that may be required
Step 1:
Scatter plot two dimensions of dataset and interpret the plots
Step 2:
Data pre-processing and scaling using normalization
Step 3:
Calculate Euclidean distance for the companies w.r.t to each other
Step 4:
Identify clusters of companies using Hierarchical clustering methods complete linkage and average linkage.
Step 5:
Plot Dendograms for Hierarchical clusters and interpret the plots
Step 6:
Compare the cluster membership using the two methods of Hierarchical clustering
Step 7:
Interpret the cluster-wise statistics
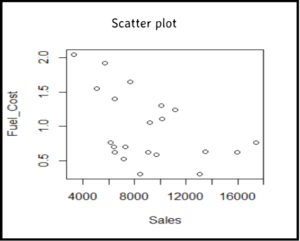
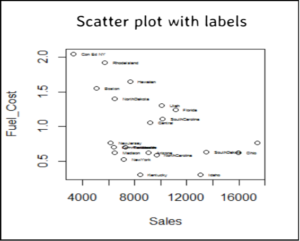
Scatter plot the data set
To identify the clusters w.r.t Fuel_cost and Sales, we scatter plot data points using these two dimensions.
#Scatter Plot two variables Fuel_Cost and Sales
plot(Fuel_Cost~Sales, utilities)
# add names next to the scatter dots
with(utilities, text(Fuel_Cost~Sales, labels=Company))
# the names and dots overlap, so lets add position to labels, pos=1 is at bottom, size of text is cex value
with(utilities, text(Fuel_Cost~Sales, labels=Company, pos=4, cex=0.4))
Interpret the scatter plot
Left side companies have high fuel_cost and low sales. In the middle companies have medium sales and medium fuel_cost. Right side low fuel cost and high sales.
So based on these two variables we have broadly identified three clusters
Data pre-processing for clustering
# we consider only quantitative data so remove 'Company' from analysis
utilities_new = utilities[,-1]
str(utilities_new)
# 'data.frame': 22 obs. of 8 variables:
# $ Fixed_charge: num 1.06 0.89 1.43 1.02 1.49 1.32 1.22 1.1 1.34 # 1.12 ...
# $ RoR : num 9.2 10.3 15.4 11.2 8.8 13.5 12.2 9.2 13 12.4 ...
# $ Cost : int 151 202 113 168 192 111 175 245 168 197 ...
# $ Load : num 54.4 57.9 53 56 51.2 60 67.6 57 60.4 53 ...
# $ D.Demand : num 1.6 2.2 3.4 0.3 1 -2.2 2.2 3.3 7.2 2.7 ...
# $ Sales : int 9077 5088 9212 6423 3300 11127 7642 13082 8406 6455 ...
# $ Nuclear : num 0 25.3 0 34.3 15.6 22.5 0 0 0 39.2 ...
# $ Fuel_Cost : num 0.628 1.555 1.058 0.7 2.044 ...
Calculate Euclidean Distance
Euclidean distances or Euclidean metric is the straight distance between two points in Euclidean space.
It shows the distance between the rows of data matrix for a column, for example, cell(11,7) is 6.05 which indicates that 11 th company and 7 th company are very dissimilar and that for cell(13,10) it is 1.40 which indicates 13 th company and 10 th company are very similar.
# calculate Euclidean distance
distance = dist(utilities_norm)
distance
print(distance, digits=3)
# 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# 2 3.17
# 3 3.70 4.92
# 4 2.38 2.28 4.07
# 5 4.30 3.87 4.55 4.28
# 6 3.62 4.23 2.97 3.23 4.66
# 7 4.00 3.42 4.25 4.01 4.60 3.35
# 8 2.75 4.02 5.04 3.66 5.37 4.96 4.52
# 9 3.29 4.48 3.11 3.77 5.26 4.09 3.61 3.46
# 10 3.01 2.81 3.89 1.49 4.21 3.86 4.54 3.62 3.53
# 11 3.50 4.83 5.91 4.83 6.56 6.01 6.05 3.49 5.26 5.04
# 12 2.29 2.79 3.78 2.69 4.40 3.65 2.39 3.03 2.21 3.14 4.81
# 13 3.85 3.52 4.31 2.56 4.90 4.57 5.02 4.04 3.52 1.40 5.24 3.68
# 14 2.11 4.38 2.77 3.17 4.98 3.49 5.00 4.34 3.83 3.54 4.32 3.66 4.29
# 15 2.68 2.46 5.17 3.19 4.28 4.05 2.94 3.97 4.56 4.26 4.78 2.49 5.08 4.30
# 16 4.04 4.89 5.28 4.93 5.95 5.85 5.13 2.22 3.66 4.48 3.43 4.03 4.32 5.17 5.23
# 17 4.54 3.62 6.40 4.99 5.63 6.12 4.58 5.61 5.55 5.57 4.87 4.19 5.69 5.68 3.43
# 18 1.92 2.90 2.72 2.60 4.41 2.83 2.99 3.31 2.87 3.02 3.96 2.12 # 3.70 2.35 3.01
# 19 2.41 4.69 3.20 3.41 5.28 2.60 4.61 4.12 4.14 4.07 4.53 3.80 4.93 1.88 4.09
# 20 3.08 3.08 3.67 1.81 4.52 2.93 3.56 4.04 2.94 2.06 5.31 2.57 2.23 3.67 3.76
# 21 3.16 2.45 5.29 2.15 4.70 4.36 3.93 3.27 3.85 2.54 4.74 2.70 2.76 4.68 3.15
# 22 2.53 2.44 4.09 2.63 3.83 4.03 3.98 3.32 3.66 2.62 3.44 2.96 2.79 3.53 3.32
# 16 17 18 19 20 21
# 2
# 3
# 4
# 5
# 6
# 7
# 8
# 9
# 10
# 11
# 12
# 13
# 14
# 15
# 16
# 17 5.68
# 18 4.00 4.48
# 19 5.23 6.19 2.51
# 20 4.77 4.95 2.85 3.83
# 21 4.27 4.33 3.55 4.74 2.17
# 22 3.48 3.65 2.51 3.98 2.66 2.50
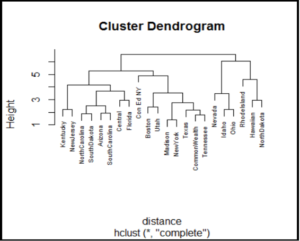
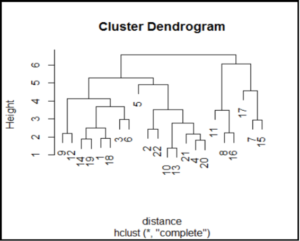
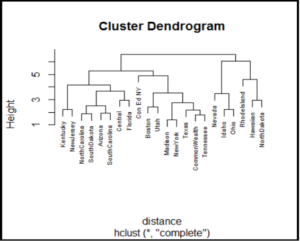
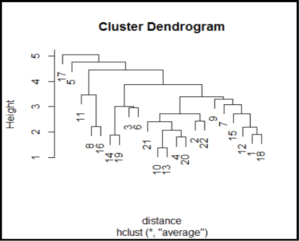
Plot Dendogram
For Hierarchical clustering using both methods, complete linkage and average linkage plot dendograms with company name as labels.
# Dendogram
plot(hCluster.cl, labels=utilities$Company, cex=0.6)
plot(hCluster.cl, labels=utilities$Company, cex=0.6)
Interpret Dendograms
Hierarchical Clustering Complete Linkage
Company 10 and Company 13 are most closely related
Hierarchical Clustering Average Linkage
Company 10 and Company 13 are most closely related
Cluster membership
Hierarchical clustering assigns members to same cluster depending on similarities. For simplicity we retrieve members of first three clusters.
# cluster membership for three clusters
member.cl = cutree(hCluster.cl, 3)
member.al = cutree(hCluster.al,3)
Cluster-wise statistics
Using aggregate function we can find the mean of each feature for members of each cluster.
For cluster 3 Sales is highest and Fuel_cost is lowest whereas for companies in cluster 2 Sales is low with highest Fuel_cost.
# cluster-wise statistics
aggregate(utilities_norm, list(member.cl), mean)
# Group.1 Fixed_charge RoR Cost Load
# 1 1 0.2488147 0.3235831 -0.2062161 0.2008503
# 2 2 -0.7267360 -0.8925964 -0.2390911 1.5517816
# 3 3 -0.6002757 -0.8331800 1.3389101 -0.4805802
# D.Demand Sales Nuclear Fuel_Cost
# 1 -0.2135522 -0.2243011 0.2619639 -0.1121726
# 2 0.1472271 -0.6608746 -0.6117317 1.3912575
# 3 0.9917178 1.8571473 -0.7854089 -0.7930034
# instead of taking normalized values you can also look at the original values
aggregate(utilities_new, list(member.cl), mean)
# Group.1 Fixed_charge RoR Cost Load
# 1 1 1.160000 11.462500 159.6875 56.08125
# 2 2 0.980000 8.733333 158.3333 63.90000
# 3 3 1.003333 8.866667 223.3333 54.83333
# D.Demand Sales Nuclear Fuel_Cost
# 1 2.575000 8150.50 18.493750 0.9059375
# 2 3.700000 6608.00 3.066667 1.6573333
# 3 6.333333 15504.67 0.000000 0.5656667